


We aim to provide a concise overview of the key fundamentals of machine learning, the challenges and the limitations. We will explain exactly what machine learning is, how it works, machine learning algorithms, practical examples of machine learning and explore the ways that it is already transforming businesses.

Table of Contents
What is Machine learning?
Machine learning is a technique of analyzing data that automates, learn and improve data models without explicit instructions. It’s a branch of artificial intelligence based on the idea that computer systems can rely on patterns with minimal human intervention.
The Basic Concepts of Machine Learning
The basic concept of machine learning is to get computers to program themselves over time by collecting data and then to react and act on it.
How they do this is through using algorithms, of which there are many, that all contain three elements.
Representation – the language that a computer understands or a group of classifiers.
Evaluation – the scoring function otherwise known as the objective.
Optimization – the search method used which is more often than not the highest-scoring classifier. Both custom and off-the-shelf methods can be used.
How Do We Get Machines To Learn?

The first way you get a machine to learn is to choose the method to be used for machine learning. There are at present four types of machine learning which are as follows:
Supervised learning (inductive learning)
Supervised learning involves using training data that already has it desired outputs included. For example, this is not a spam email, but this one is.
Semi-supervised learning
Semi-supervised learning is machine learning where a few desired outputs are included in the training.
Unsupervised learning
Unsupervised learning is where the training data are given does not include any desired outputs at all.
Reinforcement learning
Reinforced learning is the hardest form of machine learning and involves giving rewards from a sequence of actions. This is by a long way the most ambitious type of machine learning.
To get a machine to learn we also need to give them an algorithm to work with. There is a multitude of ways to achieve machine learning using algorithms such as deep learning, decision trees, neural networks, and K-means clustering.
Which one of these algorithms you use will depend on what you are trying to achieve, how much data you have and what type it is.
MORE – Data Science – 8 Powerful Applications
MORE – Computer Vision Applications in 10 Industries
A Five-Step Process of Machine Learning

1. Identify the problem
When identifying the problem you wish to solve with machine learning, you need to take three steps. First, you need to decide exactly what the problem is and describe it.
Secondly, ask yourself why this problem needs solving and the benefits that will ensue from solving it with machine learning. Finally, think about how you would solve this problem manually and without machine learning intervention.
2. Ready the data
Once you have correctly identified your problem you will need to gather the data needed. This is a hugely important step as the quantity and quality of data that you input will determine how well the machine learning will function.
When inputting the data, you have collected you should always make sure it is in a randomized order as you do not want the order in which you give the factors in the problem to affect the results you receive.
In other words, you do not want your machine learning to be dependent on or decided by the order information is received.
3. Check the algorithms
The next step in the process of machine learning is to check the algorithms are working by running 10-20 standard algorithms from all the different types of algorithm across the dataset.
The goal of this is to be able to get rid of any types of algorithm and data mixtures that are failing and to spotlight and study further those that are working well.
4. Improve the results
The fourth step in the process of machine learning is to improve on the results that you have attained. This involves:
- algorithm tuning – treating discovering the best models like a search problem.
- ensemble methods – combining predictions made by multiple models
- extreme feature engineering – pushing the limits of aggregation and decomposition
5. Present the results
Finally, you will need to present the results of the problem you have solved using machine learning. After all, the results are pretty much useless unless they are going to be put to work.
To do this clearly, whether it is for a stakeholder, or just yourself, you will want to present your results in a clear way such as:
- Why and where the problem you have solved using machine learning exists
- What exactly the problem was
- What the solution is
- What you discovered
- What the limitations of machine learning may be
MORE – Essential Enterprise AI Companies Landscape
Types Of Machine learning Algorithms

As briefly mentioned earlier there are a multitude of machine learning algorithms available to match up with the nearly limitless use of machine learning.
In fact, new algorithms are being produced every day that range from the simple to the highly complex. Here are just a few of the most commonly used:
Decision tree – This algorithm implements observations regarding actions and identifies the preferred path to get to the required destination
K-means clustering – This model places a specified amount of data points into a specific amount of sects based on shared characteristics.
Neural networks – This is an area of machine learning referred to as deep learning. It uses massive amounts of training data to recognise correlations between a large number of variables so that it can learn to process data incoming in the future.
Reinforcement learning – This is another area of machine learning that falls into the category of deep learning. It works on a reward and penalise basis that ensures the algorithm learns the optimal process.
Visual Analytics Of Machine Learning Models
The concept that machine learning models can be better understood and presented in a visual form is fairly new and only in the initial stages of being researched.
The theory, however, is that with so much going on in and around this area that visual representation may make it less difficult for us to assimilate ideas and the concepts around machine learning technology.
In a recent study on this very subject, academics at Tsinghua University in China worked with an idea that they called ‘interactive model analysis’ which was an attempt to have machine learning better understood through visual analytics.
First, they studied methods already used in the area of machine learning and then provided visual interpretations of how and why they behave in the manner they do.
Concern was however voiced in this as they believed a visual framework for machine learning may lead to uncertainties both on the part of humans and machine.
Another consideration when presenting machine learning as a visual picture is the manner in which we convert it into a visual piece. Typical tables and charts, for example, may not illustrate the dynamics of machine learning in an optimal manner.
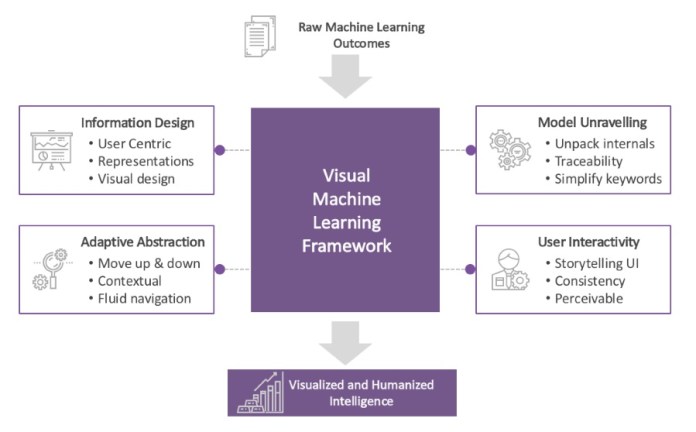
Ganes Kesari, addressed this very issue recently in an article presenting four elements to be used in visual depictions of machine learning that would ensure the aesthetics would attract the user’s attention and supply benefit.
The elements in this framework are:
1. Design Information – The interpretations of statistics should be appealing visually and have great design and user interface.

2. Adaptive Abstraction – The levels of detail and complexity involved in visual depiction should be simplified.

3. Model Unravelling – The information provided should flow in a simple and easy way that everyone looking at this visualisation will understand. This is especially true of concepts such as neural networks which are extremely difficult to ascertain.

4. User Interactivity – The way users interact with any machine learning model will heighten when the visualisation is interesting and appealing. Users find appeal more comfortable to work with.

Overall, research into machine learning visual depiction is still very much in its initial stages and will need further scrutiny before it becomes a major player.
We need to ensure that all aspects of machine learning are kept intact and that we do not compromise its workings and our understandings of them.
Examples of machine learning in companies

In 2017, billionaire Mark Cuban purchased stock in the social media platform Twitter. Now, this may not sound like anything strange after all people invest in companies all the time.
However, this was different as the decision to buy the stock was based on, as Cuban said himself in an interview with CNBC, that ‘they finally got their act together with artificial intelligence.’
Twitter, of course, is a hybrid of blogging and instant messaging at heart that also crucially reports on news, announces events, and promotes businesses.
It has over 336 million monthly users who interact with their followers. This makes it an ideal ground for the use of artificial intelligence and machine learning to enhance the user’s experience and ultimately make money for the company.
In a company blog post on June 2016, Twitter founder Jack Dorsey announced that they had bought Magic Pony Technology with the intention to ‘build the most advanced AI platform in the world.’ It renamed the division to Twitter Cortex
This translated into machine learning which consists of taking in lots of data, processing it and learning over time what content is most relevant to all their users.
It does this by:
- Considering the content of the tweet such as text, photo, and video
- Looking to see if there is past interaction between author and reader
- Considering if the tweet has a tone or content that has been previously appreciated
Ultimately, the higher the relevance the tweet has to the user the higher it will appear on their feed. Tweets of highest relevance will usually be found in the users ‘In case you missed it’ section.
Showing user‘s the most relevant and most interesting to the content is not the only use that machine learning has in regard to Twitter. It has also proved to be extremely useful and reliable in fighting inappropriate and racist content making it onto the platform.
According to the Financial Times, from January to June 2017 alone machine learning was responsible for taking down approaching 300,000 terrorist accounts.
In fact, only 5% of suspended terrorism suspected accounts are taken down by human users, 95% are the domain of AI.
Apple

You could be forgiven for thinking that Apple has shown up incredibly late to the machine learning party rather than the actuality which is that they are just fashionably late.
After all, Apple did introduce Siri, a voice assistant, to us all on a smartphone before anyone else and is planning to extend that application with a new smart home device, the HomePod.
Having said they are behind the times and have their work cut out to catch up with other companies such as Amazon and Google who already have ‘Alexa’ and the ‘Google Home Assistant’ Apple is making huge strides in other areas of machine learning.
Apple A12 AI Chip
This includes the A12 chip which has been designed within the company by their own developers and has a magnificent 5 trillion neural engine operations per second capacity.
In terms of machine learning, this has enabled the Apple iPhone to automatically recognise which tasks it should run using the GPU, which tasks it should run using the neural engine, and which tasks should be run with the primary part of the chip.
A capability which has resulted in extended battery life on a mobile phone that was already renowned for its lengthy periods between charges.
The neural engine itself is capable of complex machine learning. Following on from Apples ‘Touch ID’ the newly launched ‘Face ID’ uses an algorithm of neural networks to plot facial features. The neural engine has been trained to do this, using millions and millions of images to deter any mistakes.
MORE: Facial Recognition: All you Need to Know
On the downside, the machine learning involved in this feature does need making even more accurate in regard to features such as hair and glasses. Apple has, however, promised that this accuracy will be improved upon this year.
The neural engine can also use its neural network to capture even better pictures. With machine learning, it can make a clear decision of what is the object in the photograph and what is the background.
This is a fine example of just how fast the neural engine works considering the time it takes for you to press the shutter button and take a picture It is a fine example of just how far machine learning has come.

Probably regarded as one of the most advanced companies in the area of machine learning Google first made public their explorations of the possibilities it held in 2011 when they announced their ‘Google Brain’ project.
Just twelve months later they were back with their announcement that they had indeed built a neural network that could copy the human process of understanding and learning.
Following this, in 2014, Google acquired the machine learning startup DeepMind which was concentrating on joining an already existing machine learning technique with cutting-edge research in neuroscience.
This was a real attempt and success story in leading computers to greater resemble ‘real brains’ than they had done before.
From a practical point of view, Google has used this technology across many of its services. Image recognition was put to work initially to sort through millions of images and more accurately classify them giving Google users much more accurate search results.
Similar to Twitter it also analysed the types of viewing habits users had whilst searching for YouTube content from their servers and provided suggestions based on the information they gained. This, they have found, keeps users watching on their server and the advertising money flowing in.
More recently, early this year Google launched an artificial intelligence chat bot that can answer messages for its users on platforms such as Twitter, Skype, and Slack.
These have, however, come under some fire for machine learning perhaps being a little too clever and resulting in the use of profanity and growing bigotry.
A Brief Dip Into Deep Learning

Deep learning is basically a field of machine learning that works with algorithms that have been inspired by the workings of the human brain called neural networks.
Rather than using task-specific algorithms, deep learning uses learning data representations which can be supervised, semi-supervised or unsupervised.
For those now confused who have had experience working with or knowledge of neural networks since the 90s and early 00s perhaps this nuanced perspective from Andrew Ng in his 2013 talk titled ‘Deep learning, self- taught learning and unsupervised feature learning’ might help:
‘Using brain simulations, hope to: Make learning algorithms much better and easier to use. Make revolutionary advances in machine learning and AI.I believe this is our best shot at progress towards real AI’
ML Key Takeaways
1. Setting aside a portion of your training data for crosschecking purposes is important as you always want your selected algorithm or particular classifier to act well on new data.
2. Undeniably the most important factor in machine learning that is successful is having enough data to train your model. Features used to describe the data (domain-specific) are also of importance.
3. When algorithms do not work or do not work well it is more often than not down to a problem with the training data. This could be noisy data, skewed data or insufficient amounts.
4. Accuracy is not always down to simplicity. No correlation can be made between overfitting and the number of parameters of a model.
5. As we have no control over observational data, experimental data should be used. This could be, for example, information gained from sending varying emails to a random audience.

















{kind=link}